
Why Running Kimi Matters More Than Using ChatGPT
Building enterprise AI means validating systems, not models. Here’s how deploying Kimi locally teaches production-grade inference engineering and reliability.

How We Trained an Enterprise AI Validation Pipeline Using Kimi Instead of ChatGPT
Why building a local inference pipeline may be more valuable than changing language models.
Everyone is asking the wrong question.
“Which LLM is the best?”
For organisations, that is almost never the most important question.
The real question is:
Can we repeatedly obtain reliable answers from our own AI system?
Those are very different problems.
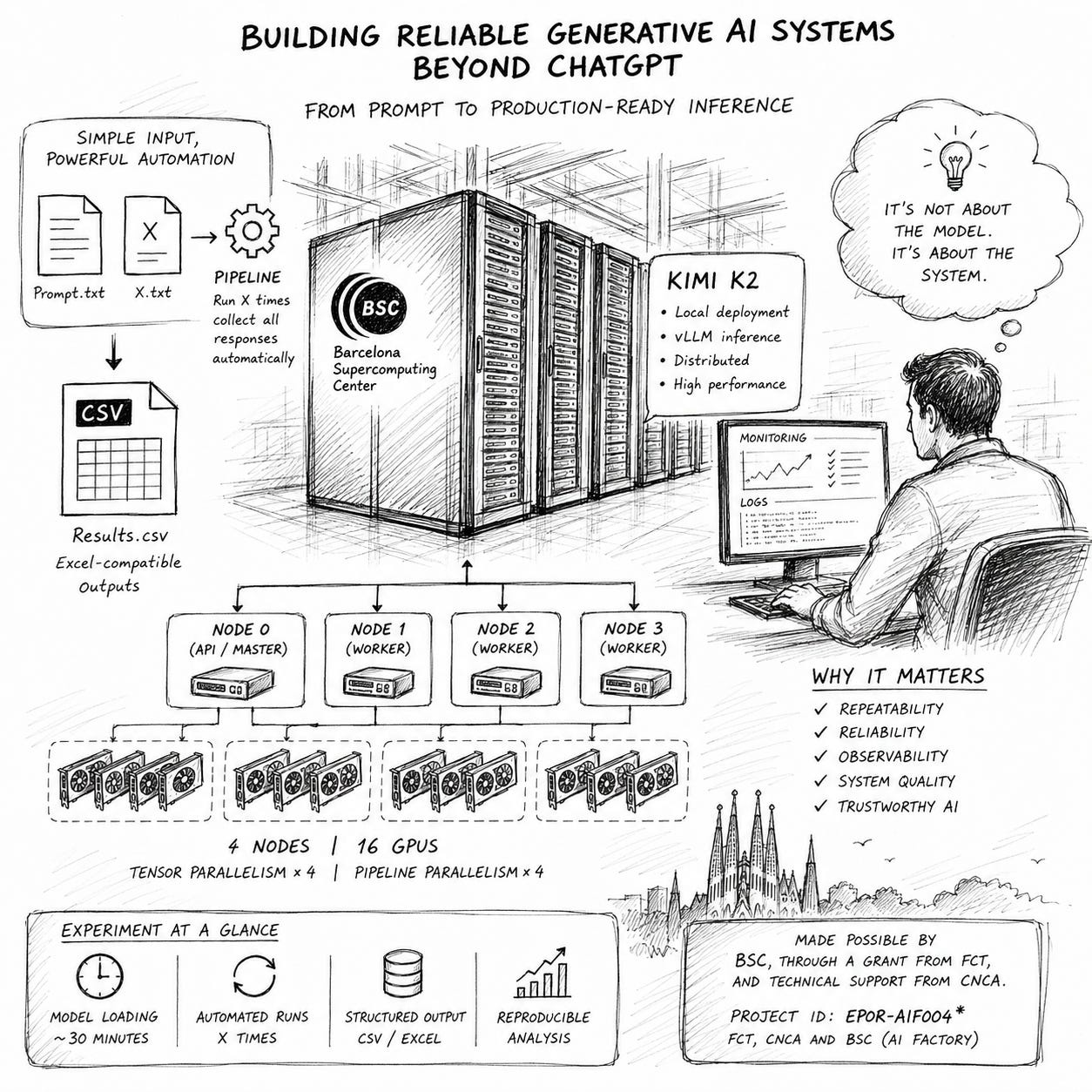
Over the last few days, I have been building a complete local inference pipeline for Kimi K2, running entirely inside the Barcelona Supercomputing Centre (BSC) MareNostrum 5 supercomputer.
At first glance, this may sound like an infrastructure exercise.
It isn’t.
It is actually one of the most valuable exercises anyone working with enterprise Generative AI can perform.
ChatGPT Was Never the Point
Many people assume that using ChatGPT through an API is equivalent to building an AI system.
It isn’t.
Using ChatGPT is consuming a service.
Running your own inference engine means understanding everything that happens between a prompt and an answer.
That includes:
GPU allocation
distributed inference
model loading
tokenizer configuration
container orchestration
networking
prompt execution
retries
monitoring
logging
result collection
failure recovery
Those components are invisible when using a hosted API.
They become your responsibility when you operate AI at enterprise scale.
The Experiment
The objective was deliberately simple.
Create a pipeline that reads:
Prompt.txt
Runs it
X times
where X comes from
X.txt
Collects every response.
Stores them automatically in an Excel-compatible CSV.
No manual intervention.
No copy-paste.
Completely reproducible.
Simple.
Reliable.
Repeatable.
Why Kimi?
The model itself is almost secondary.
We chose Kimi K2 because it is a very large reasoning model that can be deployed locally using vLLM across multiple GPUs.
Running it requires:
distributed inference
tensor parallelism
pipeline parallelism
containerised execution
Slurm scheduling
GPU orchestration
In other words:
Exactly the kind of engineering challenges organisations face when they decide not to depend exclusively on cloud APIs.
What Actually Took Most of the Time?
Surprisingly, not prompting.
Infrastructure.
The work involved:
locating the correct model snapshot
configuring the vLLM container
correcting Singularity paths
binding shared storage
debugging distributed startup
synchronising multiple compute nodes
validating GPU visibility
tuning tensor and pipeline parallelism
monitoring loading progress
handling scheduler limits
waiting for a 550+ GB model checkpoint to initialise
None of this changes the model's intelligence.
It changes whether the model can actually be used.
This Is What Enterprise AI Really Looks Like
When organisations deploy Generative AI, they are not deploying a language model.
They deploy an entire generative system.
That system includes:
system prompts
user prompts
retrieval
routing
tools
APIs
containers
inference servers
monitoring
human review
governance
Exactly the distinction described in my recent methodological framework for enterprise validation: organisations should validate the complete generative system, not the model in isolation.
That distinction becomes obvious the moment you operate your own inference stack.
Why Repeat the Same Prompt?
Large Language Models are probabilistic.
The same prompt rarely produces exactly the same answer.
That variability is not necessarily a defect.
It is part of how these systems work.
Our pipeline therefore automatically runs the same prompt multiple times.
Instead of asking:
“Did the model answer correctly?”
we ask:
“How stable is this system across repeated inference?”
This shift, from single demonstrations to repeated observations, is exactly the statistical perspective proposed in the paper. Reliable deployment requires repeated inference, prompt variation and explicit measurement of uncertainty rather than isolated successful outputs.
Check the entire paper here:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6627419
Infrastructure Is Part of AI Quality
One unexpected lesson from this exercise is that many apparent “AI failures” are not AI failures at all.
They are infrastructure failures.
Examples include:
incomplete model loading
incorrect GPU allocation
distributed communication issues
scheduler constraints
container configuration
timeout management
The model cannot produce a good answer if the system never becomes operational.
For executives, this is an important mindset change.
Reliability begins long before the first token is generated.
What We Learned
Several practical lessons emerged.
1. Operating AI is engineering.
Choosing a model is only the first step.
Running it reliably is a different discipline.
2. Observability matters.
Rich logs, progress indicators and automatic monitoring reduce debugging time dramatically.
3. Automation beats manual experimentation.
Changing only Prompt.txt and X.txt allows entire validation campaigns to run automatically.
4. Repeatability is more valuable than impressive demos.
One excellent answer proves very little.
Hundreds of controlled runs begin to produce evidence.
Why This Matters for Creative Teams
Creative organisations increasingly rely on Generative AI.
Marketing.
Advertising.
Design.
Publishing.
Strategy.
Innovation.
Yet many teams still evaluate AI through isolated examples.
That is risky.
Creative workflows deserve the same engineering discipline as financial systems.
Consistency matters.
Reliability matters.
Traceability matters.
Being able to rerun the same experiment tomorrow—and obtain comparable evidence, is often more valuable than discovering the newest model.
Building Creative Machines Means Building Reliable Systems
This project was never really about Kimi.
It could have been ChatGPT.
Claude.
Llama.
GPT-OSS (in fact, where we started, both with the 20b and the 120b).
Or the next model to be released next week.
Models will change.
Inference engines will improve.
Benchmarks will evolve.
But one principle will remain remarkably stable:
Organisations do not deploy language models.
They deploy systems.
Learning to build, operate and validate those systems may be the single most valuable AI skill of the coming decade.
Key Takeaways
Local inference teaches enterprise AI engineering, not just prompting.
Distributed deployment exposes the real operational challenges behind Generative AI.
Repeated inference is essential for measuring system reliability.
Infrastructure quality directly affects AI quality.
Enterprise validation should focus on the complete generative system rather than the underlying model alone, aligning with the statistical validation framework proposed in the accompanying working paper.
Acknowledgements
This work was made possible thanks to access to the Barcelona Supercomputing Center (BSC) through a computing grant awarded by the Fundação para a Ciência e a Tecnologia (FCT), with technical support from the Centro Nacional de Computação Avançada (CNCA).
Project reference: epor-aif004 (FCT, CNCA and BSC Barcelona Supercomputing Center – AI Factory).
Experiment at a glance
Model: Kimi K2 (≈554 GB checkpoint)
Infrastructure: MareNostrum 5 (Barcelona Supercomputing Center)
Execution: Distributed inference with vLLM 0.21
Resources: 4 compute nodes, 16 GPUs (4 GPUs per node)
Model loading time: ~30 minutes
Inference: Multiple automated runs from a single prompt (
Prompt.txt) with configurable repetitions (X.txt)Output: Structured CSV (Excel-compatible) for reproducible analysis
Recommended X via paper
More than a model benchmark, this experiment demonstrates the practical challenges and value of building reliable, repeatable, production-ready Generative AI systems.