
The Rise of Synthetic Data: What Businesses Need to Know

As we face a shortage of high-quality data to train Large Language Models (LLMs), the demand for synthetic data—artificially generated datasets like text, images, and videos—is rapidly increasing. This scarcity of real-world data pushes startups and established enterprises to turn to synthetic solutions. The synthetic data market is evolving quickly from privacy concerns to international demand. Here’s what you need to know about the current landscape.
Synthetic Training Data Startups Hit Speed Bumps
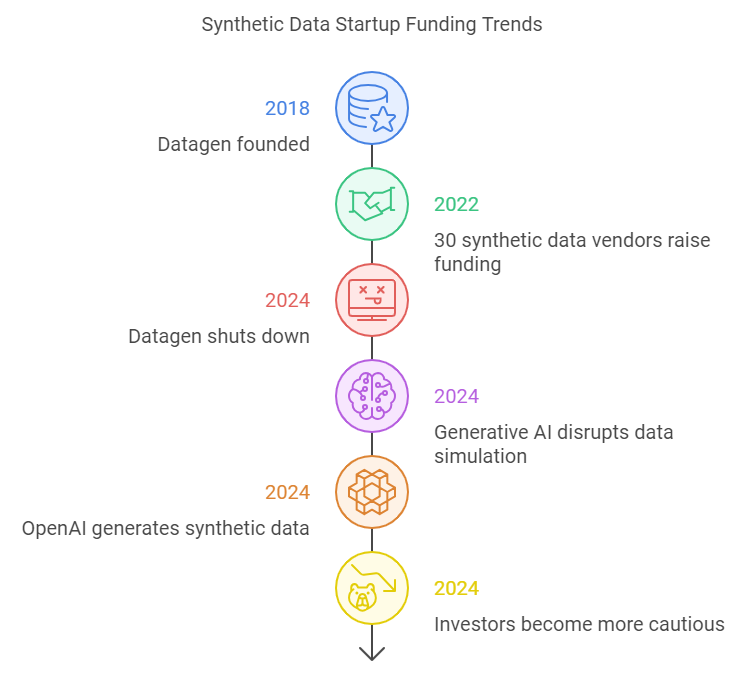
In the early days of the synthetic data boom, many startups found strong investor interest. Since 2022, nearly 30 of the 50 vendors in the synthetic data space raised equity funding. However, that trend has slowed.
What’s behind the drop-off?
Generative AI disrupted the traditional business models of data simulation companies before LLMs gained widespread attention. Take Datagen, for example. Founded in 2018, the company raised $72M but shut down in 2024 because it couldn't adapt to the rise of more sophisticated generative models like diffusion models.
Adding to the challenges, big tech players such as OpenAI are now generating synthetic data, creating a more competitive environment for startups. This has caused investors to become more cautious, focusing their capital on fewer, more resilient companies.
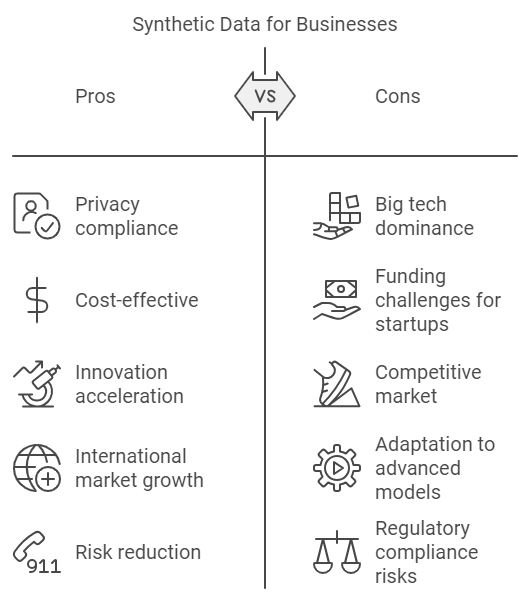
Data-Sensitive Industries Turn to Synthetic Data for Privacy
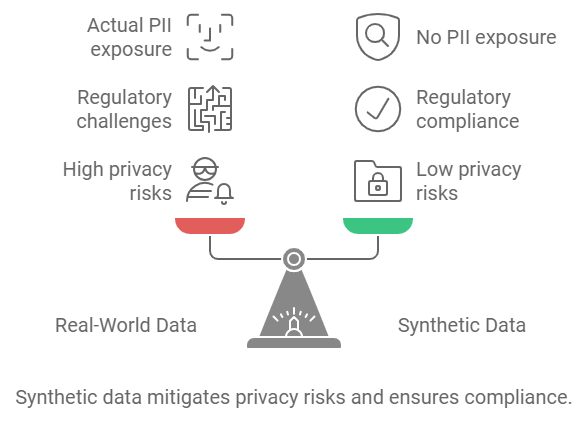
For sectors like finance, healthcare, and insurance, where data privacy is paramount, synthetic data is emerging as a powerful tool. In these industries, using real-world data can expose businesses to risks related to Personally Identifiable Information (PII) and stringent privacy regulations like GDPR. Synthetic data can offer a compelling solution.
In a recent interview, the head of AI at a Fortune 500 company explained that synthetic data allows enterprises to generate statistically identical datasets without actual customer or employee information. This not only reduces risk but ensures compliance with data privacy laws. For industries handling sensitive data, synthetic datasets are becoming indispensable in maintaining a competitive edge while staying on the right side of regulations.
Big Tech is Dominating the Synthetic Data Landscape
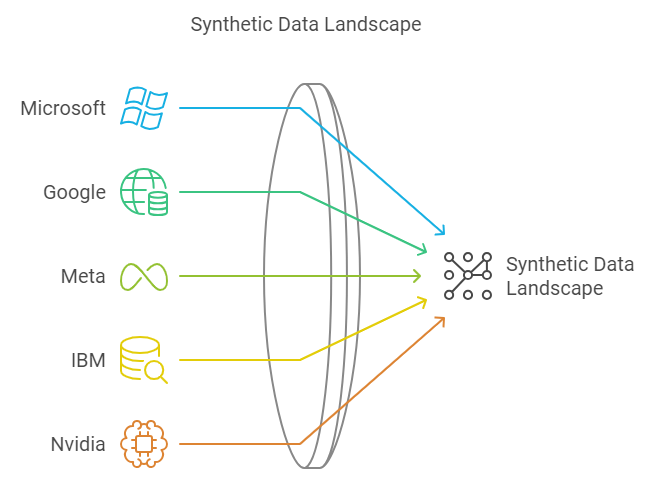
While startups may have once led the charge, tech giants like Microsoft, Google, and Meta are now critical players in the synthetic data space. These companies aren’t just generating synthetic data to train their models—they’re creating tools that allow developers to do the same.
A notable example is IBM’s recent open-source tool, InstructLab, launched in July 2024. This tool enables developers to generate synthetic data to fine-tune their models, which can lead to faster, more cost-effective model customization. Nvidia, another major player, released Nemotron-4 340B, a family of models capable of generating synthetic data specifically designed to train LLMs for commercial applications.
For startups, this increasing competition from big tech is a double-edged sword. While it drives innovation and adoption of synthetic data, it makes it harder for smaller players to secure funding and differentiate themselves in a crowded market.
International Demand is Driving Growth
Although synthetic data startups in the U.S. have seen a slowdown in funding, the international market is thriving. Over the past year, 74% of synthetic data companies with growing or stable headcounts (and a minimum of 10 employees) are based outside the United States. Countries like Italy and the UK are emerging as hotspots, with startups like Aindo and Synthesized expanding their teams and capabilities.
Why is international demand growing? Emerging regulations, such as the EU's AI Act, emphasise privacy and local data solutions. As companies scramble to comply with these regulations, synthetic data offers a way to bypass the need for sensitive real-world data while still developing powerful AI models. This trend indicates that the need for synthetic data solutions is only expected to grow, especially in regions with strict data governance laws.
Why Synthetic Data Matters for Businesses
For business leaders, synthetic data represents both a challenge and an opportunity. As companies increasingly rely on AI to drive innovation, massive amounts of high-quality training data are critical. But with traditional data sources running dry or becoming too costly to manage (both financially and in terms of compliance risk), synthetic data is becoming a viable alternative.
Industries that deal with sensitive information—like healthcare, financial services, and retail—will find synthetic data especially relevant as it enables them to innovate without exposing themselves to regulatory risks. For companies looking to develop or fine-tune AI models, synthetic data can dramatically accelerate the process while maintaining compliance with data privacy laws.
However, the rising dominance of big tech in the synthetic data space means smaller companies need to innovate quickly or risk being outpaced. For investors, this shift highlights the importance of backing synthetic data companies that can adapt to the rapid changes driven by advancements in AI, privacy laws, and global demand.
Conclusion
The synthetic data market is at a critical juncture. While startups face challenges securing funding, especially as big tech firms dominate the field, opportunities are still plentiful—particularly in international markets with strict data privacy laws. For businesses, synthetic data offers a pathway to innovation, providing the ability to train models more efficiently and privately.
As the AI landscape continues to evolve, the role of synthetic data will only grow, making it a crucial area to watch for companies seeking to stay ahead in the race for AI-driven transformation.
Main source: CB Insights
Illustrations: Building Creative Machines